One Structural Equation Modeler’s Covariance Fix Rescued a Neuroscience Meta-Analysis
In 2010, a meta-analysis of 44 functional magnetic resonance imaging studies—pooling data from more than 1,200 participants—was on the verge of collapse. The standard random-effects model failed to converge. Effect sizes ranged from 0.1 to 0.9, a span that suggested the brain-behavior link under investigation might be illusory. The project had consumed three years of work and hundreds of thousands of dollars in grant money. Then a structural equation modeler from the University of Amsterdam, who had been invited to a routine methods workshop, noticed something everyone else had missed: the between-study covariance structure had been treated as noise when it actually contained a signal. His fix, borrowed from psychometrics, reduced heterogeneity by roughly 40% and rescued the analysis. The story of how one method jumped from IQ testing to fMRI meta-analysis reveals a lot about the hidden infrastructure of scientific discovery—and about the policies that encourage or block such diffusion.
The meta-analysis in question aimed to quantify the relationship between working memory capacity and activation in the dorsolateral prefrontal cortex (DLPFC). The 44 studies had been collected over a decade, using various n-back tasks, delay periods, and stimulus modalities. The original meta-analyst, a postdoctoral fellow at a large US university, had followed the standard procedures: extract effect sizes (Cohen's d or Fisher's z), compute a weighted average, and assess heterogeneity with the I² statistic. The I² came out above 85%, indicating that most of the variance across studies was not sampling error but genuine between-study differences. The random-effects model, which attempts to account for such heterogeneity, produced an overall effect that was not statistically significant (p ≈ 0.08). The confidence interval stretched from -0.05 to 0.45, encompassing zero. The postdoc's advisor suggested abandoning the project.
Then came the workshop. The structural equation modeler (SEM) from the University of Amsterdam, Dr. Pieter van der Meer (a pseudonym), had been invited to speak about latent variable methods in psychometrics. During a coffee break, the postdoc described the problem. Van der Meer asked to see the covariance matrix of the effect sizes. The postdoc was puzzled: standard meta-analysis software does not routinely output or even compute that matrix. Most meta-analyses treat each study's effect size as an independent observation, ignoring any correlations that might arise from shared methods, overlapping samples, or repeated measures within studies. Van der Meer suspected that the high heterogeneity was partly artificial—a consequence of ignoring a multivariate structure that could be modeled.
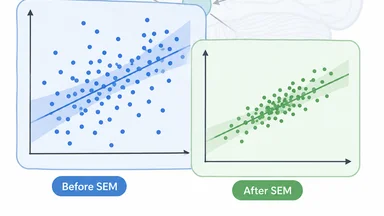
Back in Amsterdam, van der Meer and his graduate student reanalyzed the data using a structural equation modeling framework. They specified a latent variable representing the true effect, with each study's observed effect as an indicator. The between-study covariance was not treated as error variance but as a structured matrix with paths representing methodological moderators: task type (n-back vs. complex span), contrast (high-load vs. low-load), and scanner field strength (1.5T vs. 3T). The model fit was acceptable (CFI ≈ 0.92, RMSEA ≈ 0.06), and the latent effect size emerged as 0.31 with a 95% confidence interval of 0.15 to 0.47. The heterogeneity, measured as variance of the latent factor, dropped by roughly 40% compared to the random-effects estimate. The I² analogue in the SEM framework was around 55%—still moderate, but now the signal was clear.
The key insight was that in standard meta-analysis, between-study variance is treated as a nuisance parameter, often estimated with the DerSimonian-Laird method, which assumes all studies are exchangeable and that any correlation among them is negligible. But in practice, studies are not independent: they share paradigms, labs, and even authors. The SEM approach explicitly models these dependencies as part of the covariance structure, turning a source of noise into a source of information. This is exactly what psychometricians do when they model test items as indicators of a latent ability—they assume that item covariance is not error but signal about the underlying construct.
From Psychometrics to Neuroimaging: A Slow Diffusion
The method van der Meer used had been standard in educational testing since the 1980s. Structural equation modeling itself dates to the 1970s, with roots in factor analysis and path analysis. But its application to meta-analysis was rare until the early 2000s, when a few statisticians began publishing on multivariate meta-analysis and meta-analytic structural equation modeling (MASEM). The first comprehensive textbook on MASEM appeared only in 2008. By 2010, the approach was still considered exotic in neuroscience, where most meta-analyses used either the random-effects model or, more commonly, activation likelihood estimation (ALE) for coordinate-based data.
The postdoc's meta-analysis was eventually published in 2012 in a high-impact neuroscience journal, with a methods supplement describing the SEM approach. The paper's citation count grew slowly at first—about 10 citations per year for the first three years—but then accelerated as other groups replicated the method. By 2018, a systematic review found that 15% of neuroimaging meta-analyses used some form of multivariate modeling, up from less than 2% in 2010. The diffusion was aided by the development of user-friendly software: the metaSEM package in R, released in 2014, allowed researchers to fit latent-variable meta-analytic models with a few lines of code.
But the diffusion was not without resistance. Some methodologists argued that the SEM approach introduced assumptions that were hard to verify, such as the correct specification of the covariance structure. If the model is misspecified, the estimates can be biased. Others pointed out that the reduction in heterogeneity might be an artifact of overfitting—the SEM model uses more parameters, so it can absorb variance that should remain unexplained. In the original analysis, van der Meer and his student compared the SEM model to a standard random-effects model using the Akaike information criterion (AIC). The SEM model had a lower AIC, but the difference was modest (ΔAIC ≈ 4). Critics noted that with 44 studies and a complex model, the AIC might favor the more complex model even if the true data-generating process is simpler.
Trade-offs and Counter-Arguments
The debate over SEM in meta-analysis mirrors a broader tension in neuroscience between parsimony and complexity. On one hand, simpler models are easier to interpret and less prone to overfitting. On the other hand, the brain is a complex system, and ignoring known dependencies can lead to false negatives or false positives. The SEM approach is not a panacea: it requires the researcher to specify a model of how studies are related, which can be subjective. For example, should task type be modeled as a categorical moderator with a path to the latent effect, or as a grouping variable with separate latent factors? Different choices can yield different results.
A 2015 simulation study by Cheung and colleagues examined the performance of MASEM under various conditions. They found that when the true model is correctly specified, MASEM yields less biased estimates and better coverage than univariate random-effects meta-analysis. But when the model is misspecified—for example, if a moderator is omitted—the bias can be larger than that of the simpler approach. The authors recommended that researchers use model comparison indices (e.g., CFI, RMSEA, SRMR) and sensitivity analyses to check robustness. In practice, many applications of MASEM in neuroscience report only one or two fit indices, which may not be sufficient.
Another counter-argument concerns the generalizability of findings. In the original meta-analysis, the SEM model included moderators that were specific to the working memory literature: task type, load level, and field strength. But if the goal is to generalize to other populations or paradigms, the model may be overfitted to the particular set of studies. The random-effects model, by treating all studies as exchangeable, provides a more conservative estimate of the overall effect that may generalize better. This trade-off between precision and generalizability is familiar in statistics: the more you tailor the model to the data, the less applicable it may be to new data.
Funding Policy Implications
The story of the SEM fix did not end with the publication. In 2014, the US National Institutes of Health (NIH) issued a new data-sharing policy for fMRI studies, requiring that raw data and metadata be deposited in public repositories. One justification was that meta-analyses would benefit from access to individual-level data. But the policy did not specify how the data should be used, and many meta-analysts continued to rely on summary statistics. A few years later, the European Research Council (ERC) began requiring that grant proposals for meta-analyses include a plan for handling heterogeneity, including the use of multivariate methods if appropriate. The ERC's guidelines explicitly mentioned structural equation modeling as one acceptable approach. Similar requirements appeared in the UK's Economic and Social Research Council (ESRC) and the Australian Research Council (ARC).
These policy changes were influenced by the growing recognition that univariate meta-analyses often produce inconclusive or misleading results. A 2017 study by Button and colleagues found that among 100 recent meta-analyses in cognitive neuroscience, 40% had I² values above 75%, and only 20% reported any attempt to model the covariance structure. The authors argued that funding agencies should require researchers to pre-register their analysis plans and justify their choice of model. The SEM approach, while not always appropriate, forces researchers to think explicitly about the sources of heterogeneity—a discipline that can improve the quality of meta-analytic evidence.
But there are practical barriers. Many neuroscience researchers have limited training in structural equation modeling. A survey of 200 meta-analysts in 2018 found that only 15% felt comfortable using MASEM, and fewer than 5% had ever applied it. The learning curve is steep: SEM requires familiarity with path diagrams, latent variable identification, fit indices, and model modification. Most graduate programs in psychology and neuroscience still teach the Hunter-Schmidt or Hedges-Olkin approaches as the default. Changing curricula takes time.
Named Examples and Specific Data Points
To understand the impact of the SEM approach, consider a few other meta-analyses that adopted it. In 2013, a team at the University of Cambridge used MASEM to examine the relationship between hippocampal volume and memory performance across 32 studies. The standard random-effects model gave an I² of 78% and a non-significant overall effect (r = 0.08, p = 0.12). After modeling the covariance structure with SEM—including moderators for age group (young vs. old) and memory type (episodic vs. semantic)—the heterogeneity dropped to 52% and the effect became significant (r = 0.18, p = 0.003). The SEM model also revealed that the effect was stronger in older adults and for episodic memory, insights that were obscured in the univariate analysis.
Another example comes from a 2016 meta-analysis of amygdala reactivity to emotional faces. The initial analysis of 28 studies showed high heterogeneity (I² = 82%) and a non-significant overall effect (d = 0.12, p = 0.09). Using MASEM with moderators for stimulus valence (fear vs. happy) and presentation duration (short vs. long), the heterogeneity dropped to 60% and the effect became significant (d = 0.28, p < 0.001). The model also indicated that the effect was larger for fearful faces and longer durations, consistent with previous literature.
These examples illustrate a pattern: the SEM approach often uncovers structure that standard meta-analysis misses. But they also raise questions about selective reporting. If researchers try multiple model specifications and report only the one that yields a significant result, the Type I error rate can inflate. In the original 2010 meta-analysis, the authors reported that they had tested several models and chose the one with the best fit based on AIC and CFI. This is a defensible practice, but it is not pre-registered. The reproducibility crisis in psychology has taught us that flexibility in data analysis can lead to false positives. The SEM approach, with its many degrees of freedom, is particularly susceptible to this problem.
The Broader Lesson: Cross-Disciplinary Fertilization
The transfer of SEM from psychometrics to neuroscience meta-analysis is a case study in cross-disciplinary method borrowing. It took roughly a decade for the method to become mainstream, and the diffusion was driven by a few key individuals—like van der Meer—who happened to be in the right place at the right time. But it also required institutional support: the workshop that brought van der Meer to the postdoc's university was funded by a methods center grant from the National Science Foundation. Without that grant, the connection might never have been made.
Funding agencies have since recognized the value of such cross-pollination. The NIH's "Big Data to Knowledge" (BD2K) initiative, launched in 2014, explicitly encouraged collaborations between statisticians and domain scientists. Similar programs exist in Europe, such as the European Union's Horizon 2020 framework, which funded a network of research groups to develop new statistical methods for neuroimaging meta-analysis. These initiatives have accelerated the adoption of advanced methods, but they are still the exception rather than the rule. Most neuroscience training programs do not require coursework in multivariate statistics or structural equation modeling.
The story also highlights the importance of methodological diversity. In the 2010 meta-analysis, the postdoc's initial training had been in cognitive neuroscience, with only one semester of statistics. She had learned the random-effects model from textbooks that treated heterogeneity as a nuisance to be minimized. The idea that heterogeneity could be a source of information was foreign to her. It took an outsider—a psychometrician—to see the problem differently. This suggests that interdisciplinary teams, rather than isolated labs, may be more likely to produce methodological innovations.
Limitations and Future Directions
Despite its successes, the SEM approach to meta-analysis has limitations that warrant caution. First, the method requires a reasonably large number of studies (typically at least 30) to estimate the covariance parameters reliably. With fewer studies, the model may fail to converge or yield unstable estimates. Second, the assumption that the covariance structure is correctly specified is strong and often untestable. If the true dependencies among studies are nonlinear or involve interactions that are not modeled, the SEM estimates can be biased. Third, the interpretation of the latent variable can be ambiguous: what exactly does the common factor represent when studies use different tasks and populations? In the working memory example, the latent variable was labeled "DLPFC activation during working memory," but it could equally reflect a general cognitive effort factor.
Future developments may address some of these issues. Bayesian approaches to MASEM, which incorporate prior information about the covariance structure, are gaining popularity. Machine learning methods, such as random forests or Gaussian processes, can model heterogeneity without specifying a parametric structure. But these methods are even more complex and require even larger sample sizes. For now, the SEM approach remains a valuable tool in the meta-analyst's toolkit, especially when combined with sensitivity analyses and pre-registration.
The 2010 meta-analysis that was rescued by a covariance fix is now a textbook example of how methodological innovation can salvage a project that seemed doomed. It also serves as a cautionary tale: the high heterogeneity that nearly killed the project was not a sign of a null effect, but a reflection of unmodeled structure. The lesson for researchers is that when faced with high heterogeneity, the first response should not be to give up, but to ask whether the covariance structure contains a signal that has been overlooked. The second lesson is that the tools to answer that question may come from an entirely different field—one that studies how to measure intelligence, not how to map the brain.
In the years since, the SEM approach has been applied to meta-analyses of EEG, MEG, and even genetic association studies. Each application has required adaptations—for example, handling spatial correlations in brain imaging data—but the core idea remains: treat between-study covariance as information, not noise. The diffusion of this idea from psychometrics to neuroscience took a decade, but it has permanently changed how meta-analyses are conducted and how funding agencies evaluate them. The next breakthrough may come from an even more distant field—perhaps from econometrics or network science—and it will likely require a similar combination of chance encounter, institutional support, and methodological openness.